表格深度学习综述
Part1 表格任务
表格数据在工业应用中非常常见,但深度学习(DL)模型在处理表格数据时面临一些挑战,例如性能提升不明显、效率低下等。尽管近年来有一些工作声称DL模型在某些基准测试中可以与梯度提升决策树(GBDT)等经典方法相媲美甚至超越,但从实际应用的角度来看,DL模型在表格数据上的优势并不明显。
Part2 任务数据集
OpenML-CC18
Part3 领域模型
| Methods | No LLM access sample required | No LLM training required | Applied scenario | ||||
|---|---|---|---|---|---|---|---|
| No pre-training | No fine-tuning | Full data | Few shot | Classification | Regression | ||
| TabFPN (2022) | |||||||
| TabLLM (2023) | |||||||
| LIFT (2022) | |||||||
| TP-BERTa (2024) | |||||||
| GTL (2024) | |||||||
| SERSAL (2025) | |||||||
| P2T (2024) | |||||||
| FeatLLM (2024) |
TabFPN (2022)
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second, ICLR 2023
TabPFN通过在数百万个合成数据集上进行预训练,学习通用的数据分布和预测算法。这些合成数据集通过结构因果模型(SCM)生成,涵盖了线性、非线性、分类、回归等多种数据分布。预训练后的模型在处理新的真实数据集时,无需额外训练,仅通过一次前向传播即可完成预测。
TabPFN采用了为表格数据量身定制的Transformer架构,引入了双向注意力机制。每个单元格被分配独立的表示,模型可以同时关注同一行的其他特征(行注意力)和同一列的其他样本(列注意力),从而更好地利用表格的结构信息。
在小规模数据集(≤10,000样本)上,TabPFN的预测速度极快,仅需2.8秒即可超越经过4小时调优的最强基线模型。
The TabPFN still has important limitations: the underlying Transformer architecture only scales to small datasets as detailed in Appendix A; our evaluations focused on classification datasets with only up to 1 000 training samples, 100 purely numerical features without missing values and 10 classes.
TabLLM (2022)
TabLLM: Few-shot Classification of Tabular Data with Large Language Models, AISTATS 2023
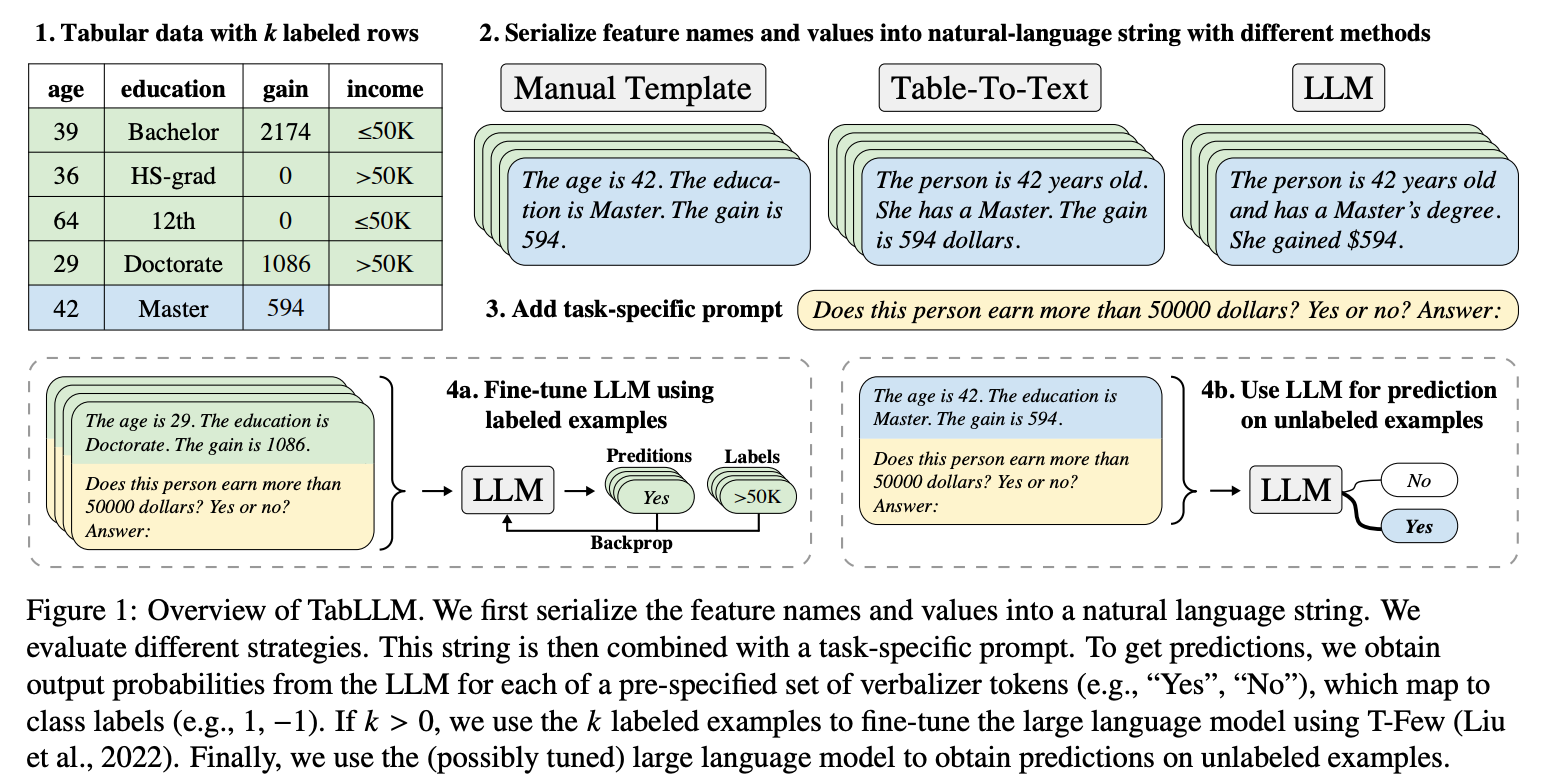
TabLLM(Tabular Language Model)是一种利用大型语言模型(LLM)进行表格数据分类的方法,特别适用于零样本(zero-shot)和少样本(few-shot)学习场景。它通过将表格数据序列化为自然语言文本,并结合任务描述提示(prompt),使LLM能够直接对表格数据进行分类。
TabLLM的核心在于将表格数据转换为自然语言文本,以便利用LLM的强大语言理解和生成能力。具体步骤如下:
- 序列化(Serialization):将表格数据的每一行转换为自然语言描述。例如,将表格中的特征名称和值组合成一个自然语言句子。
- 任务提示(Prompt):在序列化后的文本后添加一个与分类任务相关的提示,例如“这个患者是否会住院?是或否?”。
- 分类输出:LLM根据输入的序列化文本和提示生成输出,通过预定义的映射(verbalizer)将输出映射到具体的类别标签。
TP-BERTa (2024)
TP-BERTa: A Fundamental LM Adaption Technique to Tabular Data, ICLR 2024
TP-BERTa(Tabular Prediction adapted BERT approach)通过创新的数值特征处理和特征组织方式,解决了语言模型在表格数据处理中的关键难题,并在典型表格数据场景中取得了显著的性能提升,甚至在某些情况下与传统的梯度提升决策树(GBDT)模型相媲美。
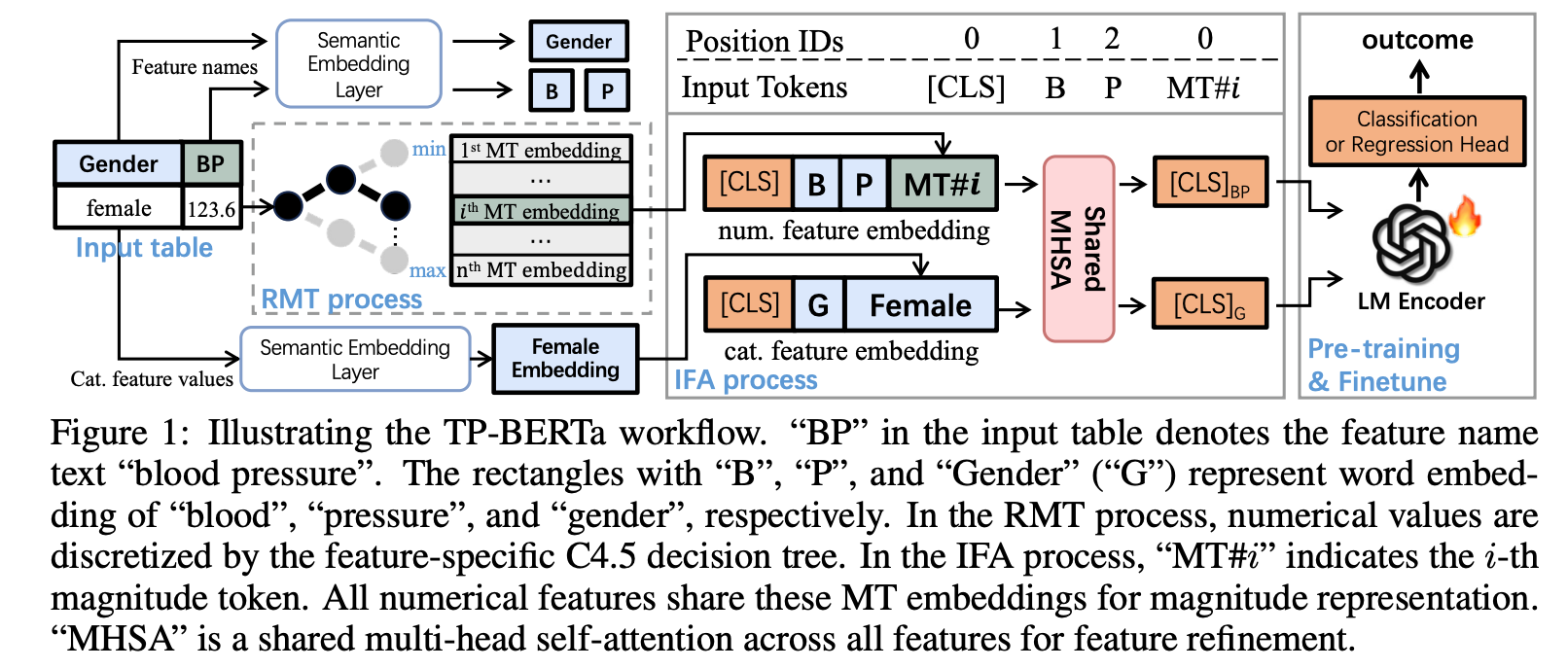
- 相对大小标记化(Relative Magnitude Tokenization, RMT):
- 数值离散化:通过C4.5决策树算法对数值特征进行分箱处理,将连续的数值特征转换为离散的“大小标记”(magnitude tokens)。每个数值被映射到一个与之对应的大小标记,这些标记在语言模型的词汇表中被表示为新的单词。
- 大小标记嵌入:为了使语言模型能够感知数值的相对大小,设计了一种“大小感知三元组损失”(magnitude-aware triplet loss)来正则化大小标记的嵌入学习,确保数值标记的嵌入在语言空间中保持合理的相对距离。
- 特征预处理:将数值特征的大小标记嵌入与其对应的特征名称嵌入进行拼接,形成一个统一的特征表示,输入到语言模型中。
- 特征内注意力模块(Intra-Feature Attention, IFA):
- 特征融合:在将特征输入到语言模型之前,IFA模块通过单头自注意力机制将特征名称和特征值的嵌入融合为一个向量,避免了语言模型在处理大量特征时的计算负担和特征值之间的错误匹配问题。
- 特征顺序无关性:通过这种设计,模型能够忽略特征的排列顺序,专注于特征名称和值之间的语义关联,从而实现特征顺序无关的预测。
GTL (2024)
From Supervised to Generative: A Novel Paradigm for Tabular Deep Learning with Large Language Models, KDD 2024
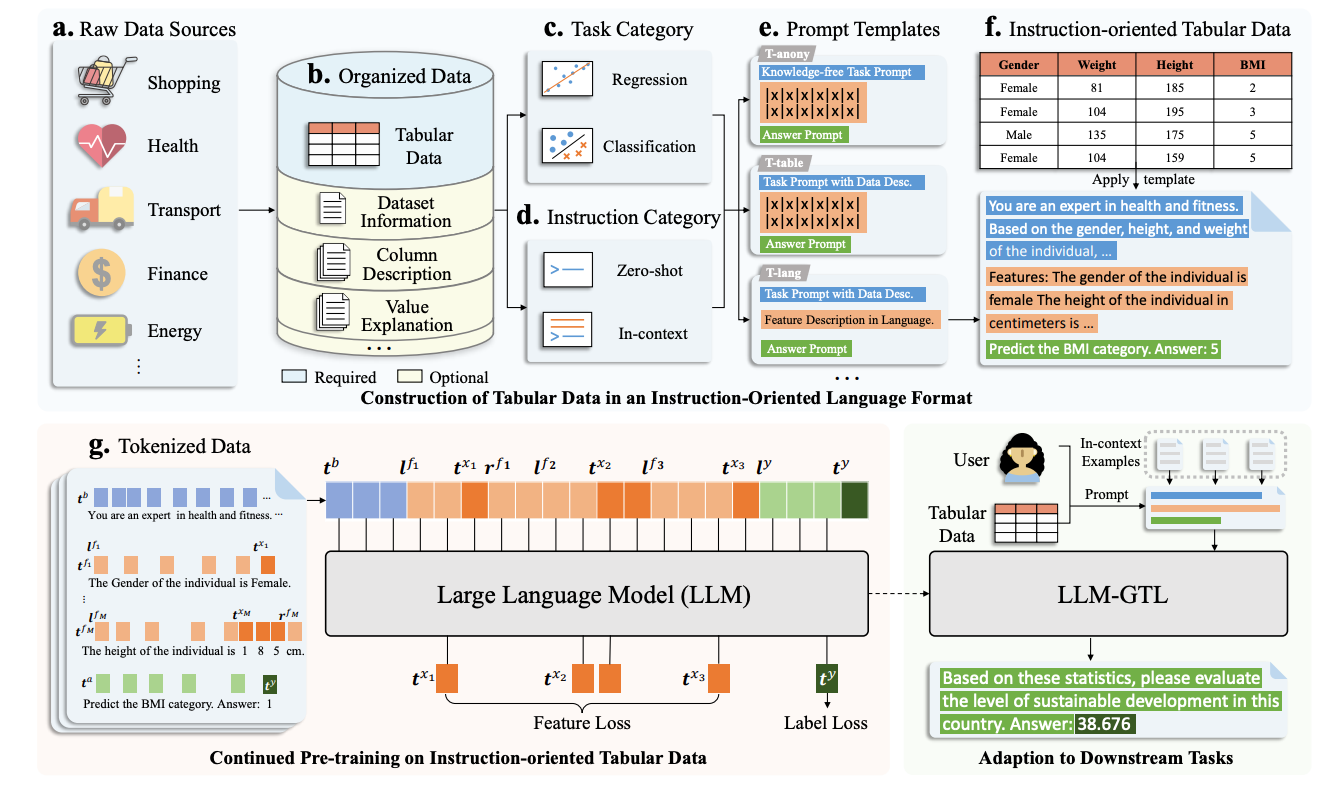
Generative Tabular Learning (GTL) 将大型语言模型(LLMs)的高级功能(如基于提示的零样本泛化和上下文学习能力)整合到表格深度学习中。
作者收集了来自 Kaggle 的 384 个公共表格数据集,涵盖 176 个分类任务和 208 个回归任务。为了将表格数据转换为指令导向的语言格式,作者设计了三种模板:
- T-lang 模板:将表格特征转换为自然语言描述,适合零样本和少样本分类任务,但在处理大量上下文示例时效率较低。
- T-table 模板:使用 Markdown 表格格式表示表格数据,适合包含大量上下文示例的场景。
- T-anony 模板:省略所有元信息,模拟缺乏背景知识的表格数据场景。
GTL 旨在通过自回归的方式学习表格数据的联合分布 ,并将其分解为特征值和目标值的条件分布。通过这种方式,模型能够捕捉特征值与目标值之间的复杂依赖关系。使用 LLaMA-2 作为基础 LLM,通过在多样化表格数据上进行继续预训练,增强模型对表格数据的理解能力。训练过程中,模型通过预测目标值的下一个标记来优化目标函数。
P2T (2024)
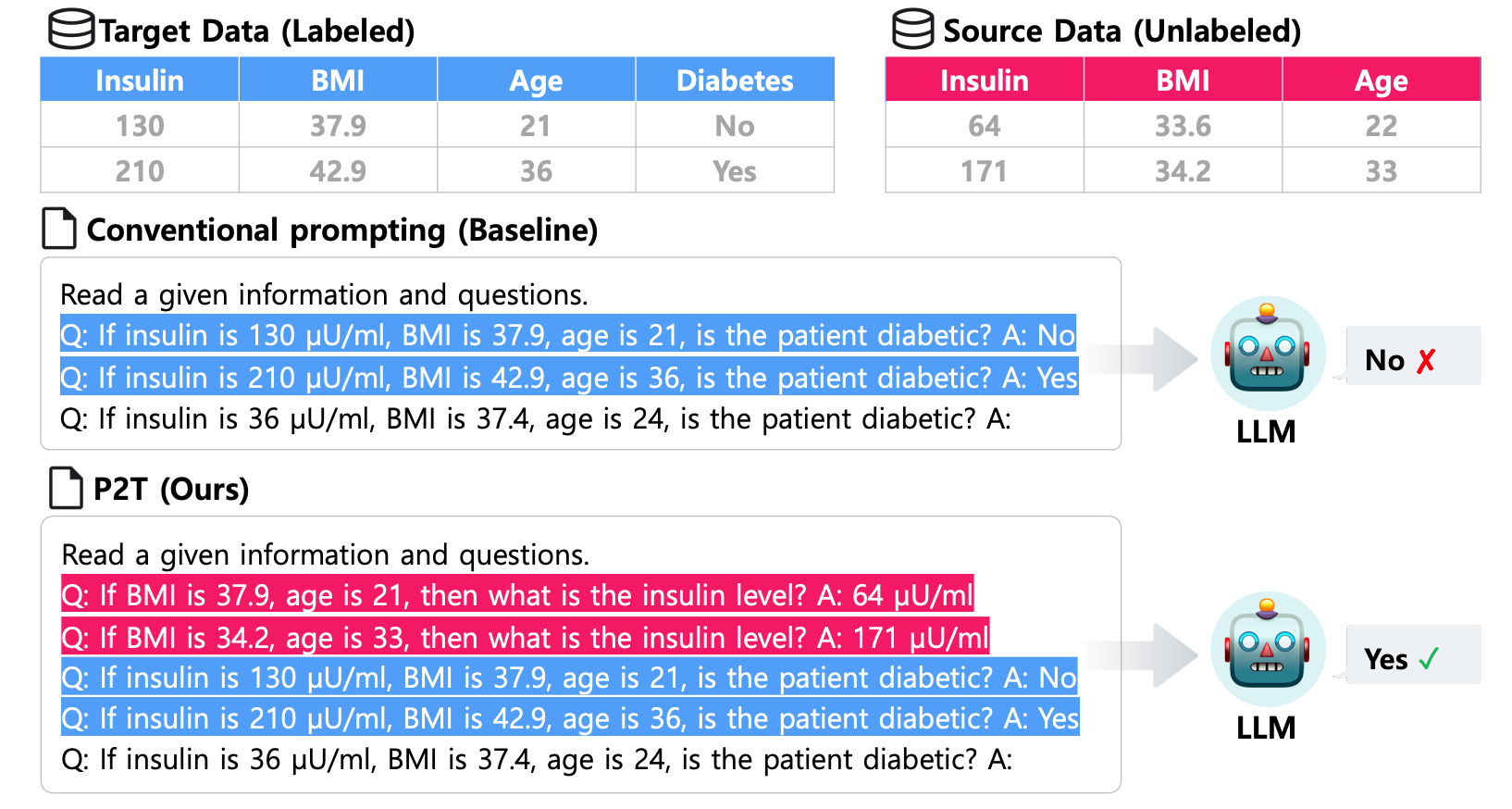
P2T框架的核心在于利用LLMs的上下文学习能力,从源数据中提取与目标任务相关的知识,并将其转化为伪示例(pseudo-demonstrations),以增强目标任务的学习效果。P2T通过上下文提示直接利用LLMs进行预测,无需对模型参数进行更新,适合快速部署和实时预测。
P2T首先通过LLMs识别源数据中与目标任务标签最相关的列特征(column feature):
- 使用目标数据中的少量标注样本(few-shot labeled samples)作为输入。
- 设计一个提示(prompt),要求LLMs从源数据的列特征中选择与目标任务最相关的特征。
- 例如,在糖尿病预测任务中,LLMs可能会选择“胰岛素水平”作为与“是否患有糖尿病”最相关的特征。
识别出相关列特征后,P2T从源数据中生成伪示例。这些伪示例将识别出的列特征作为预测目标,其余列特征作为输入。P2T将生成的伪示例与目标数据中的少量标注样本结合,形成完整的上下文提示(prompt)。
FeatLLM (2024)
Large Language Models Can Automatically Engineer Features for Few-Shot Tabular Learning
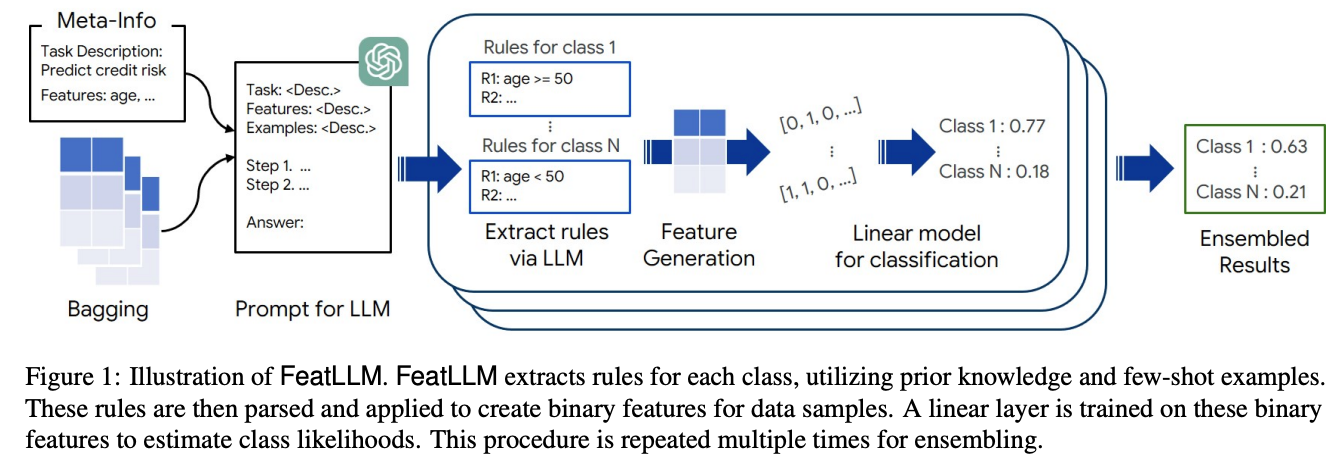
FeatLLM 的核心思想是利用LLMs提取与目标任务相关的规则(即特征条件),然后基于这些规则生成新的二进制特征。这些特征可以用于简单的下游机器学习模型(如线性回归)进行分类或回归任务。
TabM
TabM: Advancing Tabular Deep Learning with Parameter-Efficient Ensembling, ICLR 2025
TabM借鉴了BatchEnsemble的思想,通过在MLP的线性层中引入少量的非共享参数(adapters),使得每个子模型可以共享大部分权重,同时保持一定的多样性。这种设计不仅提高了模型的性能,还显著降低了计算成本。
实验结果表明,TabM在性能上优于或与现有的表格深度学习模型(如FT-Transformer、SAINT等)相当,同时在效率上具有显著优势。特别是与基于注意力机制和检索增强的模型相比,TabM的训练时间和推理速度更快。